Mar 01, 2026

Song: "One Two Three (No Gravity)", by Closer Musik
I've been working on non-mathletix things, so I thought it would be a good time to revisit some previous topics.
Tanking in the NBA only works if a team's only problem is lack of a star player.
Otherwise, it's just a cop-out for being bad, and delays or prevents fixes to organizational problems.
Oceans of ink/pixels have been spilled about tanking, including on this very website. It's a classic example of perverse incentives and unintended consequences, and most of the fixes I've seen have their own set of issues. I worked on my own proposed solution -- basically, teams could declare themselves as rebuilding at the start of the year and have a chance at top draft picks in exchange for reducing ticket prices for fans, and receiving less in revenue sharing. My idea might fix some issues, but inevitably would create other ones. Any sufficiently complex game will have some sort of meta to it that has the potential for being exploited.
Tanking is bad (nebulously defined), but trying to fix it doesn't mean the league will become better off. It's very easy to create new issues. What would a perfect league look like? Only so many teams can be contenders at one time. What do the rest of them do, that isn't tanking, but is entertaining and interesting for fans?
As I previously talked about regarding the Kings, people point to the Thunder and Spurs as evidence that tanking works, as though it's some magic elevator to success. They both rapidly became top teams in the league after a few years of intentionally being bad. The Pistons and Rockets did, too. It's easy to draw the wrong conclusions from that.
But the Thunder and Spurs already had really good organizations before they decided to be bad. Handing talented players to organizations like the Kings, that suck at everything else, feels like a massive waste, especially when it's a multi-year tank job. Can we really trust the Wizards to develop Kyshawn George into the best version of himself?
As Keith Parrish pointed out recently on the Grits and Grinds podcast, tanking also hurts coach development and evaluation. There's no way to know if a coach is good or not if you are incentivizing them to be bad. How can a coach learn to run a playoff caliber team, or win in high-pressure situations, if the team isn't trying to be competitive at the end of games? Coaches need to develop, too.
I have some confidence the coaches of the Nets and Jazz are good, because their organizations seem to actively fight them in order to keep the tank rolling -- trading away good players, (apparently) mandating good players sit out the 4th quarter, players deciding season-ending surgeries for dubious injuries. Are they going to reach their potential as coaches, when they have to deal with all this nonsense?
The Toronto Raptors have turned the corner. Last year they were intentionally bad, and this year they're pretty good. They didn't end up with a good draft pick even after fairly shameless tanking efforts last year, though. The Jazz got fined this season for not playing their best players at all in the 4th quarter of a competitive game, but the Raptors invented that crap last season.
Was it worth losing a year of experience at being a competent basketball team in order to end up with the 9th pick instead of the 12th? That's hard to believe when the player they selected, Collin Murray-Boyles, isn't clearly better than Derik Queen (13th pick) or Cedric Coward (11th pick).
Front office staff don't count against the salary cap. It's amazing to me that some insanely rich owner like Steve Ballmer hasn't offered Sam Presti a $100M a year to GM their team. It would probably still be a value, compared to the GM the Clippers just extended, Lawrence Frank. (The GM who traded SGA and the farm for Paul George, not the "What's the Matter With Kansas" guy). Getting pantsed by Sam Presti in a trade should probably be the end of any NBA GM's career.
The favorite-longshot bias & the NBA draft
There's a favorite-longshot bias at work with the NBA lottery. Bets on longshots tend to be massively profitable for whoever is offering the bets, going back to horse races hundreds of years ago. This has continued with the rise of prediction markets, which are rife with longshot sucker bets, as this great analysis shows:
Contracts trading at 5 cents win only 4.18% of the time, implying mispricing of -16.36%. Conversely, contracts at 95 cents win 95.83% of the time. This pattern is consistent; all contracts priced below 20 cents underperform their odds, while those above 80 cents outperform.
I think people take longshot sucker bets because humans are bad at estimating small probabilities. People tend not to feel numbers in the same way every time. Context matters. 1 in 17 might seem like a good chance for a tanking NBA team to get the #1 pick, but a small chance of a negative outcome when somebody's considering a risky behavior.
The expected value of getting a top pick is also prone to bias. There's a decent probability of a top pick being a bust, and a non-top pick being a great player. Yet teams and fans treat a high draft pick as a sure thing, and middling picks as being worthless. Talent isn't fixed, though. A #15 pick in the hands of a competent organization could turn into a better player than a #3 pick for an incompetent organization.
If everyone in the NBA was healthy, my top players would be Jokic (drafted 41st overall), SGA (11th overall), Giannis (15th overall), and Wemby (1st overall). People say that the worst thing to be in the NBA is in the middle, but 3 of the top 4 players in the league right now could have been drafted there.
Who knows if they would have reached their full potential if they had been drafted by a bad organization. There are plenty of non-lottery players who can be coached up, and NBA teams need to be extremely deep now, something I think many organizations undervalue. A star player can make a big difference, but there need to be pieces around them, and tanking doesn't do anything to improve the chances of getting the other 12 guys, coaching them up, keeping them healthy, establishing an identity.
As previously discussed, four of the OKC Thunder's rotation players were undrafted or selected in the 2nd round. A team looking to emulate OKC's success could do almost everything that led to it without ever tanking.
Calculating the value of tanking requires multiplying two numbers together: the odds of getting a top pick, and the odds of that pick turning into a franchise-altering player. Multiplying two overestimates together will create an even bigger overestimate.
Stupid analytics, silly hiring process edition
The Cleveland Browns made waves this offseason for their approach to hiring a new head coach. This process required candidates to write an essay about why they wanted to coach the Browns, among other indignities.
This was billed by the team as being a data-driven, analytical approach to hiring -- as if the same franchise that decided to hire DeShaun Watson for the largest guaranteed contract in NFL history should be feeling good about their hiring process.
Naturally, it attracted a lot of ire from people who think that analytics are bad, a way for nerds to feel like they're a part of sports they don't have the talent to play. The Browns are so obviously a stupid team. If they're trying to use analytics, that's proof that analytics are stupid, too.
There's some anti-intellectualism to this view, but it's not wrong when it comes to recognizing the Browns' approach is ridiculous. The reason to use analytics is to get a better, more unbiased view of sports or business or whatever. It's not enough to performatively use data, you have to use the right data in the right way, or it won't increase the odds of success.
Forcing a potential NFL coach to write a personal essay in order to get hired is a data-driven approach only in the most trivial sense. Yes, the Browns are collecting data, and basing their hiring decisions on it. But the data and the process are stupid on the face of it.
There's no reason to believe there's a correlation between being good at writing essays and being good at winning football games. Even if it had slightly positive predictive value, it's also annoying to the applicant. That probably lowers the average talent level of candidates, which will already be lower than average because they're the freaking Browns, and nobody with better options is going to apply anyway. It's adverse selection -- the sort of coaches willing to jump through their hoops are probably lower quality than ones that aren't.
The NFL combine
The NFL combine was last week. I previously covered the combine in the early days of this website. (Check it out -- it's got nice visualizations.) Many players are getting buzz from how well they did in the combine, and may have earned themselves millions of dollars by increasing their draft position, so good for them. But the combine has the potential to be stupid analytics.
Performance at the combine is definitely correlated with how high a player is drafted, but to quote the great movie Moneyball, "we're not selling jeans here. We're not looking for Fabio." The NFL is not a beauty pageant, and being a freak athlete is less valuable at the pro level, where nearly everyone is a freak athlete. The less disparity in physical abilities, the more the intangibles like mental acuity, emotional temperament, and staying healthy (which is both a skill and a talent) matter. Because drafting is such a big decision, it's perhaps natural to overfocus on the things that can be measured, like the combine, rather than the important things that can't be measured.
I've found little evidence that performance at the combine predicts how good a player will be in the NFL. I don't care about the combine, but anyone who thinks the combine matters should probably be able to prove it. The safe assumption is that it just leads to bias.
Player comps
The final bit of stupid analytics I want to touch on is player comparisons in draft guides. Articles about the NBA or NFL draft will often name a couple similar players to a prospect to give readers a feel for how they play.
It's not a bad idea, in theory. But the comps often aren't about a player's style, or how good they are, but about the innate biases of whoever's doing the comp. This NBA draft website's entry for Australian big man Rocco Zikarsky led me to some of the most egregious examples of racial profiling I've seen in sportswriting:
Superficially, Zikarsky is extremely tall, extremely white, and extremely Australian. The two comps the site gives are Mark Eaton (extremely tall, extremely white) and Luc Longley (all three). I guess it's technically "analysis", but crap like this undoubtedly does more harm than good. People who read analysis like this are less well-informed about the NBA for having read it. Bad data can be a lot worse than no data.
The site loves intra-racial comparisons, to the point that it almost seems like a running joke.
Their comps for Johnny Furphy are Sam Dekker and Gordon Hayward, two more white guys. Gradey Dick also gets compared to Hayward. Egor Demin is compared to Josh Giddey and Svi Mykhailiuk. Danny Wolf is compared to Henry Ellenson and Moritz Wagner. Brooks Barnhizer is compared to Dean Wade. Reed Sheppard is compared to Mark Price and Jimmer Fredette. Donovan Clingan is compared to Jakob Poetl and Walker Kessler. Chet Holmgren is compared to Kristaps Porzingis. Christian Braun is compared to Chase Budinger. Nikola Jokic is compared to Nikola Vucevic.
Kon Kneuppel is compared to Chris Mullin, another white guy, and Jared Dudley, a light-skinned black guy. That's as close to color-blind as they get.
The one that makes me think it's trolling is Ryan Kalkbrenner being compared to Ante Tomic, who I had to look up. He never played a minute in the NBA but was drafted in the 2nd round in 2008. How is that comparison useful for an NBA fan, when describing a player drafted in 2025? Anyone with enough hoops knowledge to know Ante Tomic should be able to think of a comparison that actually played in the league.
Sheesh. Nearly all these comparisons are laughable based on how the guys actually play. If their player comps are so obviously bad and biased, why should anyone trust the rest of their analysis? I'm not really a fan of the draft preview subgenre of sportswriting and am admittedly not the target market. Maybe the predictive power of the stories doesn't matter, like with gambling podcasters, and their cool bro stories. Why is this the story that draft enthusiasts want to hear?
Quick math time
Around 1 in 5 NBA players are white. Unless you assume there's some link between race and basketball playing style, the chances of a player's two best comps both being white should be 1 in 25, or 4%. The chances of a player having two black comps should be 64%, or 16x higher.
There should be 4x as many black players with two white comps than white players with two white comps, because there are 4x as many black players overall. Yet I've never seen a black player get two white comps, and it's pretty rare for a white player to get two black comps. Usually the comps aren't quite as blatantly biased as this site's, but there's always a little stench of it.
Last year, there was some controversy when Isaiah Hartenstein described himself as "bright skinned", because his father is half Black. Now, I have zero authority, and even less desire, to judge who should call themselves Black or not. But we can use this crappy website to make a Cleveland Browns-style data driven decision on the matter. Hartenstein's pre-draft comps? Donatas Motiejunas and Dino Radja, two white guys. That settles it!
Feb 17, 2026

Song: iiO – Rapture (Deep Dish Space Remix)
Notebook: https://github.com/csdurfee/csdurfee.github.io/blob/main/notebooks/nba-clutch-stats.ipynb
This week, I'm discussing team clutch statistics from nba.com.
Clutchness
A basketball player who tends to make good plays in high-pressure situations is known as being "clutch". When the game is on the line, who do you want taking the last shot, or guarding the other team's best player?
Like a lot of other psychological phenomena, I think "clutchness" is mostly something we notice in retrospect. It's easy to remember when our favorite players "came up clutch". It's harder to remember times when they didn't, and impossible to accurately decide whether a player is objectively clutcher than average or not based on our subjective memories, rather than using statistics.
With the hot hand phenomenon, we notice a player "can't miss" after they've already made a few shots in a row, and then they make another one. Although I've shown that the opposite of the hot hand exists in the NBA, I can't argue against the feeling that a player is on fire, or can get hot. I feel it, too. Like clutchness, some players just seem to have it, and some don't. But I think it's mostly an artifact of how we remember things.
This is perhaps reflected in the NBA's Clutch Player of the Year award. Last year, it was won by Jalen Brunson, who is a player I think NBA fans would consider pretty clutch (at least on offense). But statistically, besides scoring a lot, Brunson wasn't one of the best players in clutch time last season. His team, the Knicks, only went 17-11 (60.7%) in clutch games, which was almost exactly matched their overall record, 50-32 (61%). They won as many games in the clutch as we'd expect them to. But Brunson feels like a clutch guy. It's an award based on vibes, rather than objective facts.
This week, I'm examining team level NBA clutch statistics. The NBA formally defines clutch time as the last 5 minutes of a game, when the score is within 5 points. Obviously some threshold had to be chosen, but I wonder if a species with 4 fingers on each hand would have set the threshold at the last 4 minutes, when the game is within 4 points.
Conditional probabilities and Christmas lights
It's easy to find statistical correlations that seem important or profound, but are actually meaningless once the mess of conditional probabilities are untangled, like a box of old Christmas lights, and the right baseline is established.
An example I came across recently involves bets on NFL point totals, where you can bet on whether the total number of points scored by both teams is higher or lower than a certain number. Let's say an NFL game is a blowout -- one team wins by more than 20 points. 55% of the time, when a game is a blowout, the bet on the over wins. Is this an interesting correlation?
We might take the 55% as evidence of the rubber band effect, where teams that are ahead by a large margin tend to play with less intensity on defense, allowing the other team to score garbage time points -- scores that don't affect the outcome of the game, but make the final score look more competitive than the game actually was. It's possible the rubber band effect makes the over point total more likely to win, right?
Nope! There's a hidden conditional. In order for one team to win by at least 20 points, at least one team has to score 20 points first. In the set of games where one team scored at least 20, the over wins 60% of the time. So the game being a blowout is associated with a lower probability of the over winning, when considering those games against their true peers.
Clutch time is mediocrity time
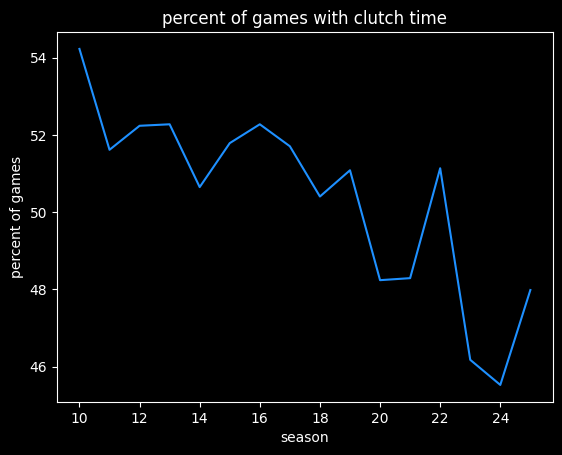
Clutch games are pretty common, around half of all NBA contests. That's stayed pretty consistent from year to year, though perhaps the rate is going down over time:
Here's a plot of each teams' winning percentage versus percentage of games played in the clutch:
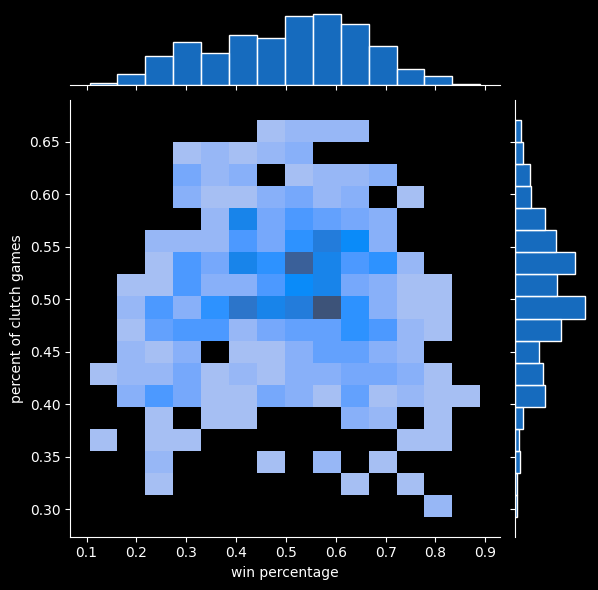
In order for an NBA game to have clutch time, it has to be a close game in the first place. Really good teams and really bad teams will be involved in fewer clutch games than teams in the middle, because they're more likely to be winning or losing by a lot.
Clutch is sort of a backhanded compliment. Houston is known as "Clutch City" because of the 1993 Rockets. (I don't know why a rocket would need a clutch, unless it is some sort of steampunk apparatus.) The team blew multiple big leads in the Finals, and just barely won the championship in 7 games. And it's unlikely the Rockets would have beaten the Bulls, if Michael Jordan hadn't been playing baseball that season. Houston only became "Clutch City" due to luck and the team's inability to finish games off. Is it really clutch to dig yourself out of a hole that you created?
There's a similar thing with NFL football. Brett Favre and John Elway are known as clutch quarterbacks because they led a lot of game winning drives. But many times, they were only in the position to have to win the game on the last drive because they threw 3 interceptions earlier.
Do especially clutch teams exist?
Teams' records in clutch situations should be close to their record overall. Here's a plot of win percentage in clutch vs. non-clutch games.
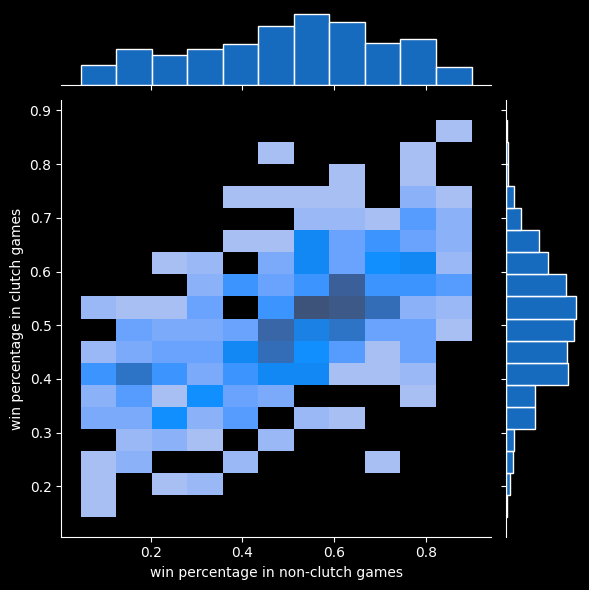
Teams that are bad tend to be bad in both clutch and non-clutch games. Teams that are good tend to be good in both. Most teams are mediocre at both.
Offense and Defensive Ratings in the clutch
Offensive and Defensive Ratings are a measure of the average number of points scored/given up by a team per 100 possessions.
There is a clear effect on these numbers in clutch time. Offensive and defensive ratings are both about 2.5 points lower in the final minutes of close games. Either offenses are worse, or defenses are better, or a bit of both. But it's a little bit harder for teams to score.
What would constitute evidence that a team actually has a special ability to win games in the clutch, versus just doing what they always do?
I decided to look at teams that are better on both offense and defense in clutch situations. For Offensive Rating, bigger is better; for Defensive Rating, smaller is better. These are the teams in the upper left quadrant of this graph:
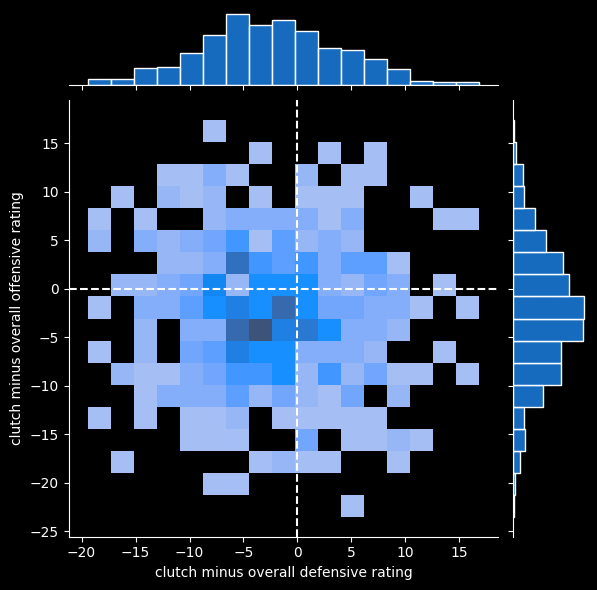
I restricted to teams that were at least 3 points better on both offense and defense. 51 teams since 2010 have met that threshold.
That set includes some great teams, such as the 2015 Golden State Warriors, who went a record 73-9 in the regular season, and 3 that won the NBA championship (2010 Mavericks, 2012 Miami Heat, and 2014 Warriors).
But the set also includes some truly bad teams, like the 2010 Cleveland Cavaliers, who went 19-63, 2013 Philadelphia 76ers, who also went 19-63, and the 2023 Charlotte Hornets, who went 21-61. 11 of 51 teams on the list didn't even make the playoffs, and 10 of them lost more games than they won.
The 40 clutch teams that made the playoffs won an average of 5.8 playoff games, versus 5.2 for all teams that made the playoffs. So these clutch teams do a little better in the postseason, but it's not a massive bump.
It's possible coaching makes a difference. There are four teams coached by Rick Carlisle on the list (2010, 2014, 2015 Mavericks; 2024 Pacers). Or perhaps certain players are significant. There are also four teams starring James Harden (2013, 2017 and 2019 Rockets; 2023 LA Clippers).
While being clutch is a positive signal, but not as strong as being a good team overall. The last 15 NBA champions average a rank of 5.3 in clutch win percentage, but 2.6 in overall win percentage on the season. Except for the 2020 Milwaukee Bucks, every NBA champion has been in the top 4 for regular season winning percentage over that stretch.
Because it's a smaller sample, performance in clutch games really should be a less accurate predictor of team success in the playoffs than their overall record in the regular season, and it is.
More on NBA clutch stats next week.
Dec 17, 2025

Song: "Pacific State (12" version)", 808 State
Two Georges, damn
In the NBA right now, there are two up-and-coming players with very similar names. This seems to keep happening in the league. I wish somebody would do something about it.
For a few years now, we've had to deal with two players named Jaylin Williams and Jalen Williams who play on the same team and have similarly generic nicknames, forcing hoops fans to remember which one is "J Dub" and which is "Jay Will". This is on top of a dozen other "Jalens" playing for other teams as well. (Do Jalen Rose or his parents get any residuals for all these basketball Jalenses? I hope so.)
Compounding the problem for Keyonte George of the Utah Jazz and Kyshawn George of the Washington Wizards is the fact they play for two of the worst teams in the league. There's only so much Jazz/Wizards basketball anyone can watch and stay sane, so even avid hoops fans should be forgiven for doing a "Christian Bale"/"Kirsten Bell" thing with them. Even pro sports journalists do that.

Both started out looking like they were drowning in the NBA, but they're putting it together, Kyshawn in his second season, Keyonte in his third, so it's time to tune in while you can still say you knew about them before it was cool.
Kyshawn
Kyshawn George is a floofy haired youth who always looks like he's 15 minutes late to his Political Science class. He should probably be playing in a North Face puffy jacket and pajama pants instead of a Wizards uniform.
 All-Pro Reels, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
All-Pro Reels, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons
With the big hair and the throwback Wizards jersey, he looks a little bit like greatest player in Washington Bullets/Wizards history, Wes Unseld:

His game is a little Unseld-y, too. Unseld was a 6'7" guy who played center. Guarding much bigger players takes a certain quality -- solidness -- that not all players have. Some guys just occupy space better than others.
Although he plays small forward, Kyshawn George has that solidness. At his best, Kyshawn just kind of owns the floor, unafraid to bounce off of other players (or go through them) in order to score or get the rebound. And like Unseld, he has good passing skills. If Wes Unseld played today, he might be a point forward like Kyshawn, who is leading the Wizards in assists.
At his worst, well, Kyshawn's got a lot to learn. I think he has the capability to be a very good defender, but the Wizards are just awful at defense -- worst in the league by points allowed. It's hard for me to tell how good a player is when they're surrounded by teammates who make lots of defensive mistakes.
Keyonte
Keyonte George, looks a bit like, I dunno, Timon from the Lion King. I don't have Timon's scouting report, but Keyonte's a super quick modern point guard who can score as well as set his teammates up. Or at least that was the idea. His first two years in the league were disappointing. He mostly shot 3 pointers, and wasn't especially good at it. As a point guard, he was tentative, and seemed to check out mentally at times when things were going bad (a frequent occurence on the woeful Jazz.)
This year, he's more of an all-around scorer, and much more efficient. He's scoring almost 6 more points per 36 minutes, while only taking 1.7 more shot attempts. A lot of that is driven by getting more free throws -- 3 more made free throws per 36 over last season. He's a threat to score from just about everywhere, after two seasons of not being a threat anywhere.
Keyonte's still bad on defense. The Jazz are 28th in Defensive Rating, so like Kyshawn, it's awfully hard to say how good he really is when he plays on such a crappy team. His game is similar to DeAaron Fox, who is currently thriving on the Spurs surrounded by significantly above average defenders. So I think he has a bright future even if he never makes a big leap on defense.
7'6" man kills giant
Shout out to the try-hard Spurs for taking down the Thunder in the NBA cup. The fact that the tallest guy in the NBA took down basketball Goliath is perfect. No notes. My biggest basketball fear is that if the aliens come down and challenge Earth to a game, we're not gonna have anyone who can guard Wemby.
Mathletix Bajillion, week I guess we're still doing this
As usual, one of these teams picks randomly, the other algorithmically.
The Ringer went 9-16 on the week, for a 171-204 combined record on the season and 45.6% winning percentage. The mathletix teams didn't cover themselves in glory either, going 3-7. Nobody knows nothin'. All of us are in the gutter, but some of us are staring at the reduced juice.
Lines taken Wednesday afternoon
The Neil McAul-Stars
last week: 1-4, -321
Overall: 16-14, +159
line shopping: +99
- SEA -1.5 -105 (prophetx)
- TEN +3 +100 (lowvig)
- CAR +3 -106 (prophetx)
- NE +3 -108 (lowvig)
- ATL -3 +100 (prophetx)
The Vincent Hand-Eggs
last week: 2-3, -110
Overall: 11-18-1, -781
line shopping: +99
- SEA -1.5 -105 (prophetx)
- JAX +3 +103 (prophetx)
- MIN -3 +109 (prophetx)
- LAC +2 +106 (lowvig)
- GB +0.5 -110 (prophetx)
Dec 10, 2025

Song: Delia Derbyshire - Pot Au Feu (1968)
Notebook: https://github.com/csdurfee/csdurfee.github.io/blob/main/notebooks/free-throws.ipynb
The Bucks
There's a lot of buzz around the Milwaukee Bucks right now because their star player has asked to be traded, but I'm gonna stick to the math. The NBA take-industrial complex has got the Giannis situation covered, and I do math better than drama.
I noted a few weeks ago that the Bucks make a surprisingly low number of free throws given that they have a guy with one of the highest free throw rates in the league. They're also bad on defense and end up fouling a lot. That's a bad combination.
As of December 5th, the Bucks are dead last in free throws made (14.4 per game) and 6th worst in free throws made by the other team (21.3 per game). Aren't they essentially having to play every game with a 6.9 point handicap?
Although it's an intuitively simple way of looking at things, it's too simple. Basketball strategy is a series of tradeoffs. There are a lot of "good" numbers -- stats that correlate with more wins -- but it's usually hard to make one good number go up without a bad number going up, or another good number going down, in response.
I'm looking at the last 25 years of team data from nba.com/stats.
Things to remember about free throws
There are complications to analyzing free throws because they're not a fixed quantity. Some fans will see a game where one team gets 20 free throws and the other team gets 35, and take it as evidence that the refs were biased. That's naive -- some players/teams foul more on defense, some players/teams take more foul-worthy shots on on offense, and there's plenty of random variation form game to game. It would be weird if every team committed exactly 30 fouls every single game.
There's seasonality to foul calls as well. On top of formal rule changes, the NBA issues points of emphasis for its officials each year, which change how the rules are interpreted. Certain types of fouls may be emphasized, or de-emphasized, causing the total number of fouls called to go up or down. It's hard to find a formal record of these de facto rule changes, but as a fan, I've seen it several times. For instance, I previously talked about the middle of the 2023 season, where the league told officials to stop calling so many fouls in general, without telling teams or the general public.
There was another shift in the early 2010's where the officials quit calling so many fouls caused by the actions of the shooter rather than the defender. A shooter can shoot in a somewhat artificial way to ensnare the defender's arms. This type of grifting still exists in the league -- looking at you, James Harden -- but the league reduced the number of cheap fouls called in the early 2010's. I couldn't find exactly when they formally made the proclamation, but we can see a big shift in the free throw data after the 2010-11 season.
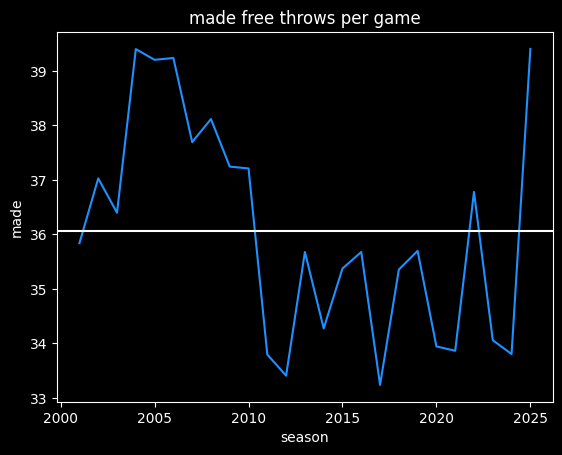
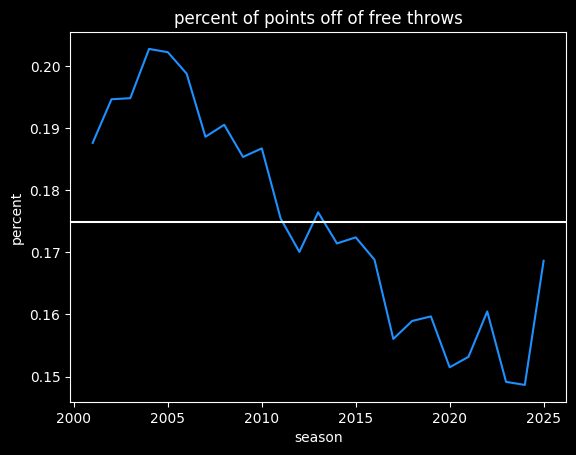
The current season has been more like the NBA from 2004-2010, at over 39 made free throws a game. However, there's a lot more scoring now, so free throws are a smaller percentage of a team's total points:
Do free throw differentials matter?
Of course, there's going to be a lot more variance in the 20 games of this season when compared to a full 82 games.
The Bucks' free throw differential of -6.9 (not nice) would be by far the worst of the last 25 years, if it held for the whole season. The Celtics' current differential of -6.3 also stands out.
90% of NBA seasons are between the two white lines. We'd expect there to be 3 outliers by the end of the season, instead of 7.
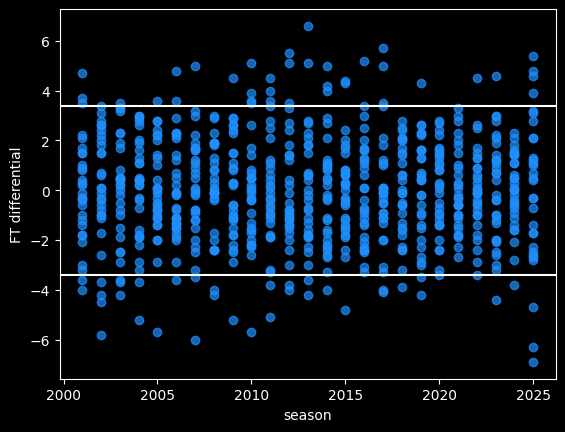
Some of the differential is due to chance. We should charitably assume that referees make random errors when calling or not calling fouls. Refs can make both Type I errors (fouls they shouldn't have called) and Type II errors (fouls they should have called and missed). Some teams will get called for more fouls than other teams, due to randomness, rather than conspiracy. Over a larger sample size, the refereeing luck will even out.
Free throw differential is positively correlated with winning.
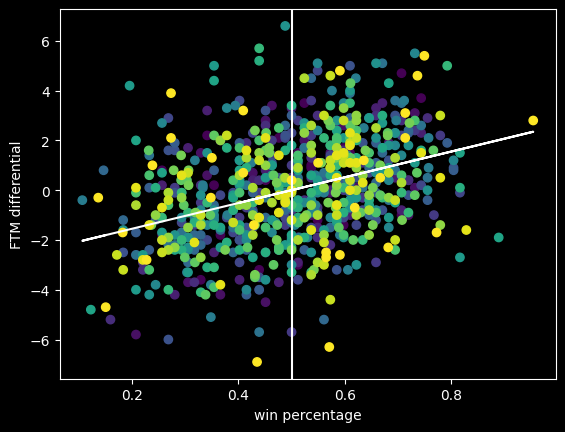
The diagonal line is the overall trendline. Even though it's a positive trend, the teams with some of the biggest positive and negative differentials are close to .500 win percentage. This is a good example of why it's important to visualize data, not just look at the correlation. The bigger picture shows it's good to have a positive free throw point differential, but not a magic ticket to winning.
Do referees try to keep fouls roughly even?
It's possible referees have an unconscious bias towards calling an even number of fouls on both teams. There's certainly a correlation between more free throws made and more free throws given up to the other team.
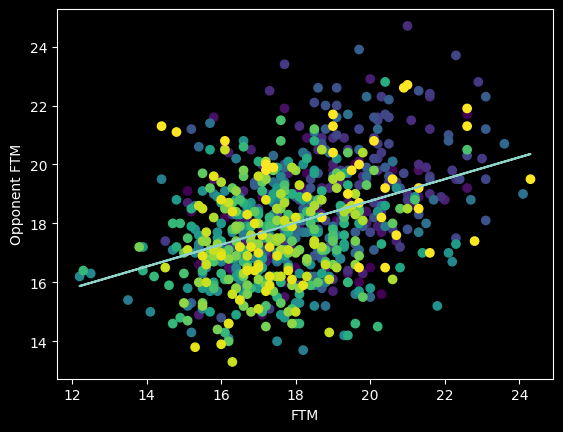
However, this overall picture is misleading. The number of fouls called per game goes up and down season-to-season based on rule changes and points of emphasis. So from year to year, the center of all the dots should move up and down along the diagonal line FTM=Opponent FTM. We should expect a positive correlation overall that isn't necessarily there in the individual seasons -- an example of Simpson's paradox.
Here's an animation of the correlations year-by-year:
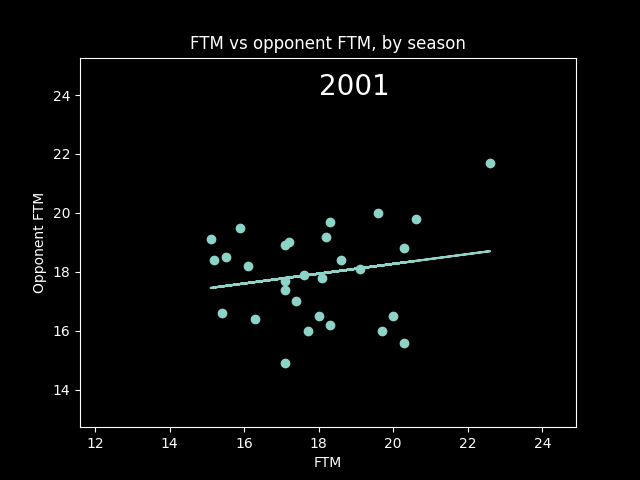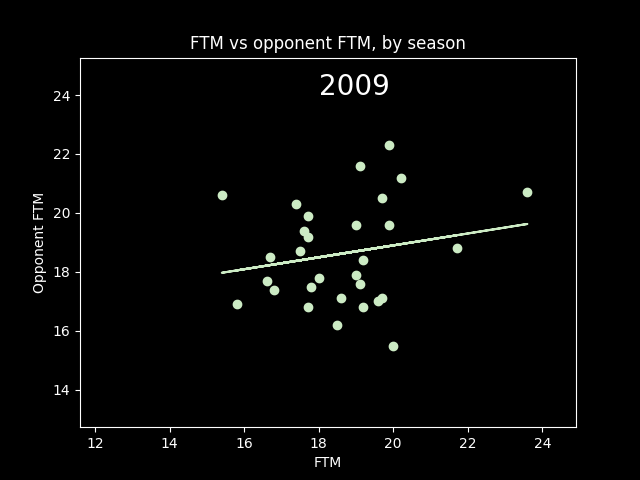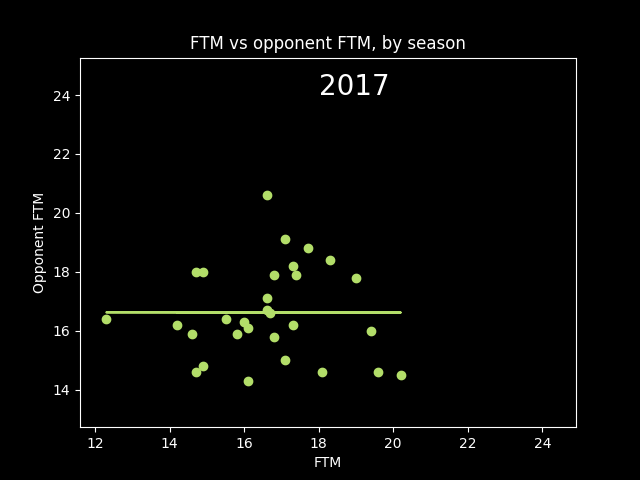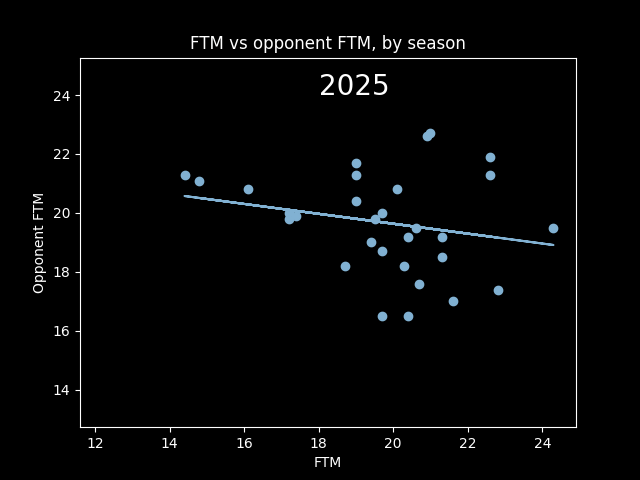
A lot of seasons, the trendline is basically flat. But plotting correlations year by year, there are a lot more positive years than negative.
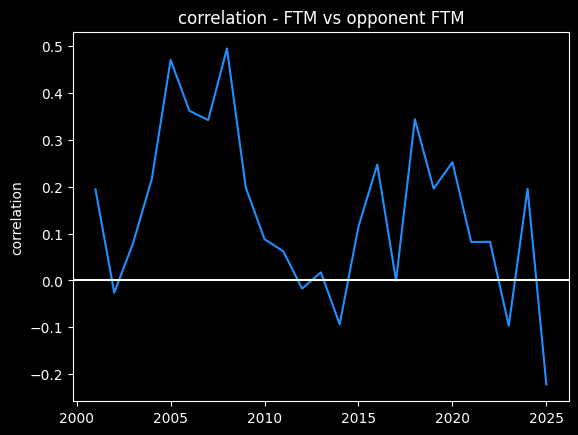
So I do think it's possible that refs call more fouls on teams that get fouled a lot, a conscious or subconscious bias towards fairness. Or perhaps, teams that play physical on offense also tend to play physical on defense as well. We'd need to look at individual games -- we're not going to see evidence of that in the yearly averages.
Basketball strategy and opportunity cost
The opponent's number of free throws made has a higher correlation with winning percentage (r=-0.260) than a team's number of free throws made (r=0.153). If it were possible to make such a binary tradeoff, the Bucks would be better off trying to foul the other team less, rather than trying to draw more fouls. That's especially true given the Bucks are the best 3 point shooting team in the league -- drawing more fouls would mean fewer 3 point attempts. They have the 2nd highest eFG%, so they're already making the most of their shot attempts.
Why isn't their offense better overall? One big reason is their offensive rebounding rate is the lowest in the league. They score the fewest 2nd chance points in the league, at only 10.5 2nd chance points a game, versus 18 a game for the top teams. Does that mean another de facto 7 point handicap?
Not necessarily, because offensive rebounding rate is a schematic choice. Do the bigs try to get the rebound (crash the boards), or do they try to hustle back and play defense? Teams coached by Doc Rivers tend to have low offensive rebounding rates. The "Lob City" Clippers were a great rebounding team, yet in their heyday from 2014-2018, they were 21st, 28th, 29th, and 24th in offensive rebounding, so it's not surprising the Bucks have that same tendency.
The Thunder have the 3rd fewest second chance points, so a team can definitely be elite and not get a lot of offensive rebounds. But unlike the Thunder, the Bucks are bad on defense (22nd in defensive rating) and foul way too much, so they're not in a good place to make defense their identity. If this were NBA 2K, I'd probably move the "crash the boards" slider to the left for the Bucks and see what happens, because the Bucks are closer to being elite on the offensive end. There's more strength to build on.
There is only a very slight positive correlation between 2nd chance point differential and winning percentage. It's a bad predictor of team success.
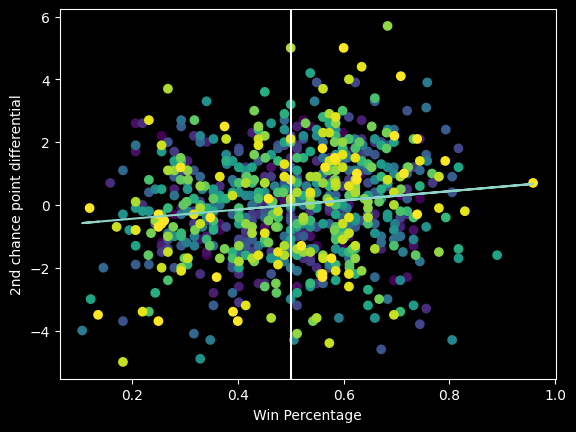
The Nets are fun... for now
The Brooklyn Nets had a bunch of draft picks and cap space going into this offseason, and they didn't seem to maximize those resources. A lot of people didn't like the trade they made for Michael Porter Jr., which got the Denver Nuggets out of salary cap hell in exchange for a fairly small return. The Nets were the only team in the league with the financial flexibility to take on bad contracts in trades, so they probably could have gotten more.
They also didn't trade any of the five first round picks they accumulated in this year's draft. Why didn't they trade some of them for future picks? The conventional wisdom is that teams shouldn't try to develop too many rookies at once. What's a team supposed to do with five rookies (two of whom are teenagers), with some overlap in the positions they play?
Well for one thing, they're supposed to be terrible. The Nets have been bottoming out for a few seasons, and I doubt that will stop this season. Catch them in the next few weeks while they're sort of trying to win games, if you're curious. They've won 3 out of their last 4 games and they've been entertaining.
They were fun for a few weeks at this point in the season last year, too. The front office will probably try to trade away their best players over the next couple of months to keep them from being too good. But right now, MPJ is a good stats/bad team All-Star, Nic Claxton is solid as always, rookie Danny Wolf is already a fan favorite, and a couple other rookies show promise.
As fun as they are, I'm not encouraged by the Nets' approach to rebuilding. I'm always a lot more concerned with process than outcomes, because the process can be controlled. It seems like their idea is that if they draft enough first rounders, inevitably some of them will be good. It's treating players like lotto scratch tickets -- players are inherently winners or losers, and it's the front office's job to play the percentages and get as many picks as possible.
That's bad process to me. Players are more like a packet of seeds. The final result is heavily dependent on how and where they are grown. The same seed grown in two different environments can give two very different results. Some seeds are better than others, but without the right environment, even the best seeds won't grow to their maximum potential. I don't know if they have the culture and support system to develop their five rookies. It will be a few years before we'll see what sort of trees they're growing in Brooklyn.
The Mathletix Bajillion, week whatever
As usual, one set of NFL picks is algorithmic, the other is random.
Mathletix won the week, with a total record of 6-4 versus the Ringer's 10-15 record (note: their website incorrectly lists The Handicapos as going 5-0 when they actually went 4-1. I'm petty enough to notice, but not petty enough to email them about it.)
The Ringer currently has 3 teams at 33-37 and 2 teams at 31-39, for a cumulative record of 161-189 (46.0% winning rate). Of course, some of the Ringer's picks contradict each other -- one Ringer team taking the home team, and another taking the away team on the same game. Removing the bets where Ringer teams contradicted each other would just make things worse, though, because taking both sides of a bet has a winning percentage of 50%, which is better than the Ringer's overall win rate.
Someone taking the opposite of every one of the Ringer experts' picks would be up 11.9 units on the year, for a +3.4% rate of return. There's only a 6.7% chance of getting results that bad by flipping a coin.
As I've written about before, I don't think that makes them bad as far as gambling experts go. Rather, I believe everything they know about football has already been incorporated into the line, so their knowledge is kind of a curse -- they're overvaluing information that the market has already absorbed, so they end up losing more than 50% of the time.
Lines taken Wednesday morning
The Neil McAul-Stars
last week: 4-1, +304
Overall: 15-10, +480
line shopping: +80
- CIN +2.5 -101 (lowvig)
- NYG -2 -110 (hard rock)
- MIA +3.5 -105 (lowvig)
- BUF PK -110 (lowvig)
- NYJ +13.5 -105 (prophetX)
The Vincent Hand-Eggs
last week: 2-3, -108
Overall: 9-15-1, -671
line shopping: +79
- PHI -11.5 -105 (lowvig)
- DET +6 -105 (lowvig)
- WAS +2.5 +105 (prophetX)
- KC -4.5 -109 (prophetX)
- CIN +2.5 -101 (lowvig)
Dec 02, 2025

Song: Hobo Johnson, "Sacramento Kings Anthem (we’re not that bad)"
Stats are as of 12/1/2025. Spreadsheet here
The Kings
The Sacramento Kings are going through it. Again. For most other teams, the choices they've made recently would be a historically incompetent period, a basketball Dark Ages. For the Kings, it's just another season.
Firing the only coach that's had success with the team in a long time and replacing him with a buddy of the owner who is willing to work cheap. Drafting two All-Star point guards and trading both of them away. Trading for two guys (LaVine and DeRozan) who everybody knew would be a bad fit from their years playing together on the Bulls. Trading the very good, ultra reliable Jonas Valančiūnas for the washed Dario Saric just to save a tiny bit of money.
Do you know the definition of insanity? The Kings' front office doesn't.
Sacramento is 5-16 so far. They're definitely not a good team, but maybe they're not that bad? They went 40-42 last season, which is respectable in the loaded Western Conference. They've had a brutally hard schedule, and 21 games is not a large sample size.
I'll get back to the Kings, but first, the other side of the coin.
The Heat
The Miami Heat were arguably in a worse place than the Kings at the end of last season. They won 37 games, 3 fewer than the Kings, and play in the easier conference. They looked totally checked out by the end of the season, another team stuck in the middle of the NBA standings.
It was a disappointing, dysfunctional run where they traded away their best player and seemed to be going nowhere. The vibes were bad, but they didn't blow up the team for the hope of maybe being good again someday, or run back the same players and the same scheme for another bout of mediocrity. Instead, they trusted the culture they built and tried something innovative.
They've been one of the best stories in the NBA so far, greatly outperforming expectations by playing a radical brand of basketball on the offensive end. They completely overhauled their offense to quickly attack one-on-one matchups before the defense can get set, rather than the traditional approach of creating mismatches using pick-and-rolls.
Here's a good video from Thinking Basketball explaining the strategy, an even more turbo-charged version of the scheme the Grizzlies used to great success last year. As a basketball fan, it's a bit weird to watch at first, because pick and rolls are such an traditional part of basketball, but it's refreshing.
I don't know why more teams don't have the courage to try unconventional things -- or in the Grizzlies' case, stick with something unconventional that was working. In the NBA, it takes a great coach and front office to defy the conventional wisdom and try to get more out of the players already on the roster -- putting them in a position to succeed rather than re-shuffling the deck.
The most remarkable part is that overhauling the offense hasn't sacrificed the Heat's identity as a top-tier defensive team at all. They have the 4th best defense in the league so far by Defensive Rating. They're doing this while playing at the fastest pace in the league this year. Teams that play fast are usually just trying to outscore their opponents, with little attention to defense.
But the Heat are using their scheme to generate high quality offensive opportunities for players that are primarily on the court for their defense. They're building on their core identity rather than changing directions entirely. They're building on strength.
An elite playmaker like Tyrese Halliburton, or a generational talent like SGA or Jokic, can set up defense-first players for easy looks, but most teams that concentrate on defense struggle generating enough offensive firepower. The Orlando Magic have been plagued by that problem for years. The system Miami is running seems like a cheat code for defensively minded teams -- at least until the league inevitably figures out ways to slow it down.
I couldn't find anybody in the media who knew the Heat's scheme change was coming, much less an idea of how much of an impact it would have. I looked at a bunch of preseason power rankings, and they were all pretty down on the Heat for the same reasons, without any hint that they could fix the problems with a different play style. It's much easier to assess the impact of roster changes.
For example, this is from NBC Sports' preseason power rankings:
this was a middle-of-the-pack Heat team last season that made no bold moves, no massive upgrades, leaving them in the same spot they were a year ago.
Here's Bleacher Report's
for an offensively challenged team, replacing [Tyler Herro's] scoring (21.5 points over the last four seasons) and distribution (4.6 assists in the same span) is going to be tough.
And USA Today's:
Losing Tyler Herro for the first two months of the season, potentially, comes as a significant blow to a team that struggled to score — especially late in games — even when he was on the floor.
With the change in style the Heat are still only a mid-tier team on offense, ranking 14th in Offensive Rating. But that's a big step up from last year, when they were 21st, especially given they haven't had their best offensive player for the first month of the season.
Are they going to win a title with the present roster? No, but in addition to giving their fans something to cheer for, all their players will look much better on paper than they did at the start of this season. If they do decide to trade players, the Heat can get more in return for them. And it's not hard to get free agents to move to Miami if the team is winning and the vibes are good, so they could be a real contender again quickly.
It's weird that tanking is seen as the best way to increase the chances of future success in the NBA, rather than building a winning culture and innovating. The two teams with the most success in recent years at doing a major rebuild have been the Spurs and the Thunder. They were both bad for a few years, but they're also two of the best run teams in the league. They draft well, they trade well, they do player development well, they do analytics well. They had a clear vision of the type of team they wanted to build and the clear ability to develop players. If a team doesn't have those organizational competencies, what's the point of a tank? They're just going to waste their high-level draft picks, not develop the rest of the roster, and be mediocre again in 5 years.
Power ranking the power rankers
I collected data from six preseason NBA power rankings. There's a link to the spreadsheet at the top of the article. I would've liked to collect more data, and I'm sure there are other sites that did good NBA power rankings, but stuff like that is basically impossible to find these days, lost in a sea of completely LLM generated baloney or locked behind paywalls. It's not useful interrogating why some LLM stochastically decided that the Warriors are the 4th best team in the NBA this year, but there's seemingly an endless supply of that type of nonsense. Which is to say: thanks for reading this, however you managed to get here. I hope you'll keep coming back for this completely human generated baloney.
I compared the rankings from each list to each team's point differential, which is a better estimate of how good a team is than their win-loss record. How good were our mighty morphin' power rankers at predicting the current standings?
So far, the most accurate ranking has been RotoBaller's, with a Spearman correlation of .76. The worst has been USA Today, at .69. Taking the median rank of all six sources produced a correlation of .74, which was better than 5 out of the 6 individual scores. So we're getting a "wisdom of crowds" effect, which is interesting, since all the rankings are fairly similar to each other. (Previously discussed in Majority voting in ensemble learning.)
I also included rankings based on my own preseason win total estimates. I got a score of .73, right in the middle of the pack. That's respectable, but I can't believe I'm getting beat by the freaking New York Post.
Comparing rankings to records, the power rankers were too high on the Clippers, Cavaliers, Pacers, Kings and Warriors. They were too low on the Raptors, Suns, Heat, Spurs and Pistons.
Strength of schedule
Scheduling matters. Some teams have played much harder schedules than others, and we're dealing with small sample sizes, so win-loss records can be deceiving early in the season.
I grabbed adjusted Net Rating (aNET) data from dunksandthrees, which calculates the offensive and defensive ratings for each team, adjusted for strength of schedule. I also included Simple Rating System (SRS) data from basketball-reference, which is the same idea as aNET, but a different methodology.
The difference between aNET and average point differential gives a sense of which team records might be the most misleading compared to the team's actual skill level. For instance, the Sacramento Kings have already played the Thunder, Nuggets and Timberwolves three times apiece, going 2-7 over those games. Even a decent team would be expected to have a losing record against those opponents.
Based on aNET, the Cavaliers, Warriors, Clippers, Kings and Celtics are probably better than their records indicate.
Going the other way, the Raptors have had a deceptively easy schedule, going 7-1 in games against the woeful Nets, Hornets, Pacers and Wizards. Going 7-1 doesn't tell us much, because those are teams pretty much everybody should be able to beat.
The stats indicate that the Raptors, Hornets, Spurs, Jazz, and Suns are probably not as good as their records.
Most of the teams the power rankers got wrong have been hurt or helped significantly by their schedules so far. The biggest exception has been the Miami Heat, who apparently nobody saw coming, and are probably about as good as their record says they are.
The Kangz
What to make of the Kings? According to basketball-reference, they've had the hardest schedule in the league so far. It's fair to say they're not as bad as the record says.
While they're 28th in point differential, they're 25th by aNET, and 26th by SRS. So they might have 7 or 8 wins instead of 5 if they'd played a league average schedule. That's not that much, though, and a clear step back from last year.
Their rookie, Nique Clifford, has not looked good so far, and they don't have many players that other teams would want in a trade. It doesn't seem like they have any clue of how to develop young talent. Their highest paid player, Zach LaVine, has another year on his contract, doesn't play defense, and has put up a -1.1 VORP this year. They just benched their one big signing of the offseason (Dennis Schröder), and are instead starting Russell Westbrook, a man born during the Reagan Administration playing on a one year minimum deal.
On paper, they don't have much they can do to get better. But everybody was saying that about the Heat at the end of last year, and look at them now. I just can't see the Kings having that type of organizational courage, but I hope they find it somehow rather than spend years on another doomed rebuild. Sacramento fans deserve better than another version of the current mess. At least an innovative mess would be a change of pace from trying the same stupid thing over and over. What's the worst that could happen?
Sacramento's roster isn't great, but like the Grizzlies, the biggest problems I see are organizational. I understand the Kings are a rich man's toy, not a serious basketball team, but wouldn't it be more fun to own a team that wasn't a giant tire fire? I don't get spending billions of dollars to buy a sports team just to run it into the ground like this.
The Mathletix Bajillion, week 5
As usual: One of these teams picks NFL games randomly, the other uses a simple algorithm.
4 of 5 Ringer 107 teams had a losing week, going 10-15 collectively. All five still have a losing record on the season, so right now the McAul-Stars are the undisputed leaders.
Bluster aside, the important thing to notice is how much they're saving taking cheaper lines than the standard -110 odds. The McAul-Stars would be up +110 instead of +176 if the bets were taken at a retail sportsbook, and the Hand-Eggs would be down -620 instead of -563.
Lines taken Tuesday morning. Since it's early in the week, the reduced juice isn't quite as juicy as usual.
The Neil McAul-Stars
last week: 4-1, +296
Overall: 11-9, +176
line shopping: +66
- SEA -7 -108 (lowvig)
- DAL +3 -104 (prophetx)
- CIN +5.5 -108 (draftkangz)
- JAX +2 -108 (prophetx)
- LAC +2.5 +108 (prophetx)
The Vincent Hand-Eggs
last week: 1-4, -316
Overall: 7-12-1, -563
line shopping: +57
- WAS +1.5 +100 (lowvig)
- CIN +5.5 -108 (draftkangz)
- LAR -8 -101 (prophetx)
- DEN -7.5 +100 (lowvig)
- CLE -3.5 -108 (prophetx)
Nov 28, 2025

Song: The Jimi Hendrix Experience - Voodoo Child (Slight Return) (Live In Maui, 1970)
Jimmy Butler: still good
Last season, Jimmy Butler quiet quit on his team. He wanted a new contract from the Miami Heat, and they didn't want to give him one, so he just stopped trying. As a fan, it seemed like an annoying and entitled thing to do. He couldn't just play the season out?
Butler eventually ended up getting traded to the Golden State Warriors, who gave him the extension he wanted, and he started trying again.
Setting aside whether Butler was justified, was the extension worth it or not? Butler is 36 years old, an age where it's totally expected for players to start to decline. The NBA salary cap rules now make it so a team can't afford to get a contract as big as Butler's wrong.
The Warriors took a calculated risk, and it paid immediate dividends when Jimmy helped them sneak into the playoffs last year, but the team is about in the same position they were before they got him -- a few high level players, but not in the upper echelon of the league due being old and incomplete.
Jimmy's doing great, though. He's at career highs in True Shooting (TS%) and effective FG percent (eFG%).

He's always been an efficient scorer, due to his ability to draw a lot of fouls. That means shooting a lot of free throws, which are easy points. Jimmy has been getting about 2.4x the number of free throws per shot attempt compared to the league average.
That's about where he's been for several seasons now. His free throw rate saw a huge jump when he moved to the Miami Heat in the 2019-2020 season, and he's maintained that ever since:
The career highs in TS% and eFG% probably aren't sustainable, though. Butler's a career 33% 3 point shooter who's making 45% of them this season. I wouldn't bet on that continuing, but he'll always be valuable on offense if he can draw that many free throws.
Butler's defense is still great, as well. The Warriors are 6.5 points per 100 possessions better on defense when he's on the floor.
He stands out on all the advanced metrics. Right now, he's 4th in WS/48 (behind Jokic, Shai and Giannis), 8th in PER, 8th in VORP, 3rd in Offensive Rating, 8th in Box Plus/Minus, and 11th in EPM.
For the numbers he's putting up, I think he's worth the money.
Ewing theory, 2025 edition
Individuals don't win games, teams do. Sometimes it can be hard to tell how much of player's individual contribution is actually increasing the likelihood of their team winning. And there's always opportunity cost: perhaps a big man would've been more valuable to this team than Butler has been.
When a star player gets injured, sometimes a team plays better, a phenomenon Bill Simmons coined "The Ewing Theory". We're seeing some of that this year.
The Atlanta Hawks are 2-3 this season when star Trae Young plays, and 9-4 when he doesn't.
The Memphis Grizzlies are 4-8 when star Ja Morant plays, and 2-4 when he doesn't. (While the win percentage is the same, the team has looked less hapless in those 6 games.)
The Orlando Magic are 6-6 when star Paolo Banchero plays, and 4-2 when he doesn't.
All three players have distinctive play styles that their team must run to maximize their talents -- to paraphrase James Harden, they are the system. Sometimes maximizing the opportunities for the best player means wasting some of the talents of the other players on the team.
Similar distinctive players like Harden, Jokic and Halliburton are far more essential -- their teams are much worse when they are out, despite the same potential on paper for holding their teams back.
What's the difference between the Hawks, who have been doing better without Trae Young, and the Pacers, who are completely hapless without Tyrese Halliburton? I'm not going to read too much into such small sample sizes, but it's an interesting thing to watch out for.
SGA's FTAs
Debates involving subjects anybody can have an opinion about tend to be much louder than subjects requiring specialized knowledge. It's the law of triviality. The purest form of this in sports is the question of who is the most valuable player. TThe NBA version of this debate is probably the loudest and least interesting of any sport.
There are people who don't know much about basketball or statistics, but will argue endlessly on the internet whether BPM or EPM or RAPTOR or VORP is the right metric for deciding who is the best player. Or rather, they decide on the player they like, then find the statistic that says what they want to hear.
For me, the MVP usually comes down to personal preference -- there are always a handful of players that are clearly better than everybody else, and which one is the most valuable among that set is a matter of taste, and often gets decided by narratives rather than anything rigorous. Perhaps rigor is futile. Pretty much every MVP caliber player is a unique basketball talent. None of them are really interchangeable -- they all break the mold in some way. Any sort of all-in-one number is bound to fail at capturing what makes each one special.
Perhaps because it is a matter of taste and ultimately a very trivial question, people tend to latch onto style points. Who is funnest to watch, who would be the funnest to play with. Who scores points ethically and unethically.
People who think that Shai Gilgeous-Alexander (SGA) shouldn't be the MVP derisively call him FTA, implying he gets awarded more free throws than he deserves, or is otherwise a free throw merchant -- someone who baits defenders into fouling him.
Shai is currently currently the leader in FTAs this year, so the FTA nickname is accurate in one sense. Here are the 10 players with the most free throw attempts this season, plus Jokić (15th place.)
| Name |
Attempts |
FTr |
FTr+ |
PPG |
| Shai Gilgeous-Alexander |
167 |
0.465 |
164 |
32.2 |
| Luka Dončić |
150 |
0.551 |
194 |
34.5 |
| Deni Avdija |
143 |
0.472 |
166 |
24.9 |
| Devin Booker |
141 |
0.416 |
147 |
26.4 |
| James Harden |
139 |
0.488 |
172 |
27.8 |
| Franz Wagner |
136 |
0.471 |
166 |
23 |
| Giannis Antetokounmpo |
132 |
0.532 |
188 |
31.2 |
| Jimmy Butler |
132 |
0.667 |
235 |
19.9 |
| Pascal Siakam |
130 |
0.444 |
156 |
24.8 |
| Tyrese Maxey |
125 |
0.334 |
118 |
33 |
| Nikola Jokić |
116 |
0.395 |
139 |
29.6 |
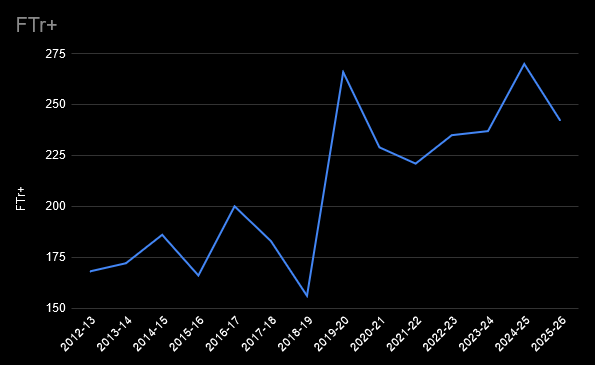
Shai's FTr+ of 164 indicates he gets 1.64x more free throws per shot attempt than the average player.
In a vacuum, that seems high, but everybody on this list has an FTr+ of over 100. They're all good at drawing fouls. Most high volume scorers are. They score a lot and get fouled a lot for the same reason, they're hard to guard. Jimmy Butler is the king, though -- the only player on the list averaging under 20 points a game, and the only one with an FTr over .600.
Jimmy's getting 2 free throws per every 3 shots he attempts. Since he makes 80% of them, that's a free half point Butler gets every time he attempts a shot. As far as free throw merchants go, he's Giovanni de' Medici.
Compared to his peers, SGA's free throw rate is pretty tame. It's 7th on this list -- lower than Luka Dončić, Deni Avdija, James Harden, Franz Wagner, Giannis, and Jimmy Butler.
It's a little higher than Jokić's, but I don't know how you decide that an FTr+ of 139 is ethical, but an FTr+ of 164 is unethical (or a sign that the refs are in the tank for SGA). Where's the line? Why do other MVP candidates like Luka and Giannis escape criticism, when they draw more fouls per shot than SGA does?
I'll take a deeper dive into the topic some other time, but the fact that Luka's free throw rate took a jump when he got traded to the Lakers is another example of why the NBA stands for Not Beating Allegations.
Mathletix Bajillion, week 4
As usual: one team picks randomly, one team uses a simple algorithm.
Both the mathletix teams have losing records now, but so do all 5 Ringer teams, so it's still anyone's game. We're still saving a lot of (imaginary) money by shopping for lines, instead of taking them at -110. Even though I got lazy with shopping, I still managed to find all 10 bets at reduced juice.
Lines as of Friday morning.
The Neil McAul-Stars
last week: 1-4, -323
Overall: 7-8, -120
line shopping: +60
- MIA -5.5 -104 (prophetX)
- HOU +3.5 -107 (prophetX)
- WAS +6 -108 (prophetX)
- CAR +10 -108 (prophetX)
- NE -7 +100 (prophetX)
The Vincent Hand-Eggs
last week: 3-2, +97
Overall: 6-8-1, -247
line shopping: +33
- LV +9.5 -104 (lowvig)
- CLE +5 -104 (prophetX)
- PHI -7 -108 (prophetX)
- PIT +3 +100 (lowvig)
- WAS +6 -108 (prophetX)
Sources
All data sourced from basketball-reference.com
Nov 19, 2025

Song: Talking Heads, "Cities", live at Montreaux Jazz Festival, 1982
What's going on with the Grizzlies?
The easiest answer is they're miserably bad on offense. It's also the oddest thing about this team to me, since they scored effortlessly last year. The Grizzlies had found something that worked last season. They had the 6th best Offensive Rating, and 10th best Defensive Rating. Considering the Indiana Pacers made it within one game of winning the NBA Championship with the 9th best Offensive Rating and 13th best Defensive Rating, the Grizzlies were definitely a borderline contender.
This year, they're 27th in Offensive Rating, 21 positions worse than last year. (The falloff on defense is a little more understandable, since they have several very good defensive players injured right now.)
eFG+ is a measure of effective FG%, normalized so that 100 is league average. Here are the top 8 Grizzlies players by minutes played the last two seasons:
| Position |
2025 |
2024 |
2025 eFG+ |
2024 eFG+ |
Diff |
| Center |
Jock Landale |
Zach Edey |
108 |
111 |
-3 |
| PF |
Jaren Jackson Jr |
Jaren Jackson Jr |
98 |
101 |
-3 |
| SF |
Jaylen Wells |
Jaylen Wells |
82 |
97 |
-15 |
| SG |
KCP |
Desmond Bane |
77 |
104 |
-27 |
| PG |
Ja Morant |
Ja Morant |
71 |
93 |
-22 |
| Bench 1 |
Santi Aldama |
Santi Aldama |
96 |
106 |
-10 |
| Bench 2 |
Cedric Coward |
Scottie Pippen Jr |
105 |
102 |
3 |
| Bench 3 |
Cam Spencer |
Brandon Clarke |
109 |
115 |
-6 |
Except for rookie Cedric Coward, every single slot is a downgrade. Wells and Aldama have been significantly worse than last season, but the most dramatic is Ja Morant. The only player with around as many minutes played and a lower eFG+ are Ben Sheppard and Jarace Walker of the Indiana Pacers, young players who have been forced into playing a lot of minutes due to injuries.
Where have all the backup PGs gone?
A big problem for the Grizzlies is that they don't really have a backup point guard. They're far from the only team with a lack of PGs on the roster this season.
The Dallas Mavericks have been playing rookie forward Cooper Flagg as PG even though they knew their starting PG, Kyrie Irving, was injured coming into the season. The Nuggets have been experimenting with having forward Peyton Watson as backup PG. The Houston Rockets have no true PG in their "oops, all bigs" starting lineup, though Reed Sheppard is playing more and more off the bench, and looking pretty good.
It's an odd trend to me. Backup point guards have traditionally been cheap and easy to find -- guys like Ish Smith and D.J Augustin. They're like small, functional trucks. They made a ton of them back in the day, but they kinda don't exist anymore, despite how useful and reasonably priced they were. Does that make Yuki Kawamura the Kei truck of this analogy? Yes, yes it does.
The Rockets and Nuggets are doing fine so far without playing a backup PG, but the Grizzlies' situation is just baffling to me. Ja Morant is one of the more injury prone players in the league. You didn't think you needed to find a real backup for him? (Wouldn't Russell Westbrook look good in a Grizzlies uniform?)
The Grizzlies have a stretch of easier opponents coming up, so I think they'll start looking a little better for that reason alone. Maybe they'll get some mojo back. But I'm always about process, rather than outcomes, and I just don't get the Grizzlies' process right now. They had something pretty cool going last year, and now they don't.
Teams can't control a lot of factors. Injuries, who they play on a given night, the bounce of the ball on the rim on a last second shot. There's a lot of luck. But the Grizzlies' problems seem to come down to things the coaching staff and front office can control: vision, planning, vibes, communication, style of play.
Mathletix Bajillion, week 3
One of these teams is random, one is chosen by an algorithm put together by me, a non-football guy. Can you guess which one is which?
All lines are as of Thursday morning.
The Neil McAul-Stars
last week: 1-4, -301
Overall: 6-4, +203
line shopping: +43
- PIT +2.5 -105 (lowvig)
- GB -6.5 +100 (lowvig)
- NO -2 -108 (prophetx)
- TB +6.5 +101 (prophetx)
- PHI -3 -110 (hard rock)
The Vincent Hand-Eggs
last week: 2-2-1, -10
Overall: 3-6-1, -344
line shopping: +16
- CIN +6.5 -107 (rivers)
- CHI -2.5 -105 (lowvig)
- ATL +2 -102 (prophetx)
- BUF -5.5 -101 (prophetx)
- DET -10.5 -102 (prophetx)
Nov 18, 2025

Song: "Round 6", by Prince Jammy
A few interesting statistics from the first dozen games of the 2025-26 NBA season.
I'm generally talking about stats per 100 possessions, rather than raw stats (unless otherwise noted).
The absurd OKC Thunder
The OKC Thunder have been a godless basketball killing machine this year. Almost every win is a blowout, despite their second best player being injured. They look like they don't even have to try all that hard, and they're winning by an average of 16 points.
To me, their secret sauce is that they make it nearly impossible to score against them. There are no easy buckets. Here are some good ways to get easy points in the NBA:
- make lots of 3's
- get lots of free throws (and make them)
- take a lot of shots close to the basket
- get points off of turnovers
- get out on the fast break
- get second chance points
The Thunder are middle of the pack at the first two. They're only 15th in 3 pointers made against them per game, and 12th in free throws given up.
They're ridiculously elite at everything else that makes scoring hard. The Thunder are first in the league at:
- Defensive Rating
- Defensive Rebounding
- Steals
- Fewest opponent fast break points
- Fewest opponent points in the paint
- Fewest opponent points scored
- Lowest opponent effective FG%
They're second in the league at:
- Fewest turnovers
- Fewest opponent points off turnovers
- Fewest opponent 2nd chance points
- Fewest opponent assists
- Most opponent turnovers
The most remarkable part is how they've built their team. Their 3rd and 4th leading scorers, Ajay Mitchell and Aaron Wiggins, were both 2nd round draft picks. Their 5th leading scorer, Isaiah Joe, was a 2nd round pick by the 76ers who got waived, then refurbished by the Thunder like an estate sale armoire. Their best defender, Lu Dort, went undrafted.
The team just finds a way to bring the best out of players that any other team could have had. What did they see that everybody else missed, and what did they do to develop them?
As a fan of another NBA team, and someone who lived in Seattle in the 15 years after the Sonics were stolen away to OKC, I want to get off Mr Presti's Wild Ride. But statistically, it's great.
Bucking trends
Victor Wembanyama is by far the best shot blocker in the NBA, averaging 3.6 blocks a game. But the Spurs are only 6th overall in blocks. Nikola Jokic is by far the best passer in the NBA, but the Nuggets are only 5th overall in assists. Steph Curry is the best 3 point shooter of all time. But the Warriors are only 12th in 3 point percentage. This isn't all that surprising. Just because one player is good at a particular skill, that doesn't mean the rest of the team is.
What's more surprising to me is that Giannis Antetokounmpo draws the most free throws in the league, but the Bucks are 28th in free throw attempts. Teams that get a lot of free throw attempts tend to attack the basket a lot, or be the Los Angeles Lakers. The Bucks are weird because pretty much only Giannis does anything free throw-worthy. At the time I wrote this, Center Myles Turner had not shot a single free throw in his last 63 minutes of game time. That doesn't seem like a recipe for success for the Bucks.
Basketball is broken
And I know the guy who did it: Nikola Jokić. Advanced stats aren't everything, but right now he has a Win Shares per 48 (WS/48) of .441. Win Shares are probably a little biased towards big men who score efficiently, and affected by the pace of the game. That aside, it's a pretty good stat as far as having a single number to quantify how good somebody is at basketball. It correlates pretty strongly with actual basketball watching, I think. The top players in WS/48 are usually the top candidates for the MVP every year. And it matches who we think the best players are historically.
Last year, the top player by WS/48 was Shai Gilgeous-Alexander, at .309. The year before, it was Jokic, at .299. The year before, it was Jokic at .308. In 2014, it was Steph Curry, at .288. In 2004, when the pace of play was slower, the leaders were Nowitzki and Garnett at .248. In 1994, it was David Robinson, at .273.
Pretty much anything over .250 is an MVP caliber season. There's really no historical precedent for a WS/48 of .441. After 12 games played, Jokic could be the worst player in the league for the next 7 games, and he'd still be having an MVP-type season overall.
Before last game, it was .448. What did Jokic do last game that caused his WS/48 to go down a tiny bit? He got 36 points, 18 rebounds, and 13 assists, on good scoring efficiency and only 2 turnovers. That's a slightly below average game for him right now.
The perils of hand-rolled metrics, pt. 137
I was trying to put together something to show how historically off the charts OKC has been defensively. I started with using a fancy technique, PCA, before realizing that just adding up the ranks of each of the statistics was better and simpler. If one team is 1st in blocks, 2nd in steals, 2nd in opponent points in thde paint, etc., just add the ranks up, lowest score is best.
I ran it on every team over the last 15 years. All of the teams that did well on my metric were good defensively, and the teams that did poorly were putrid on defense. It's not totally useless. But it's a bad way to find the best teams of all time.
Here are the top defensive teams since 2010 by this metric:
- the 2025-26 OKC Thunder
- The 2018-19 Milwaukee Bucks (won 60 games with peak Giannis)
- The 2010-11 Philadelphia 76ers (last Iguodala season, young Jrue Holiday)
- The 2019-20 Orlando Magic (Aaron Gordon and some guys)
- The 2017-18 Utah Jazz (the "you got Jingled" meme team that beat OKC)
Ah well. That's not a terrible list. They were all very good at defense, and made it a big part of their team identity, but I don't think those are really the best defensive teams of the last 15 years. A team's rank by Defensive Rating is still a better predictor of the team's win percentage than my attempts.
There's definitely some Goodhart's Law potential here. OKC are near the top of a bunch of statistical categories, because they are good at defense overall. You can't necessarily get on their level just by trying to copy specific things OKC does well, like prevent fast break points.
We see you, Jalen Duren
More like Jalen Durian, because some of the things he's doing are just nasty. You will definitely get kicked off the bus in Singapore if you're watching Jalen Duren highlights.
Data used
All data from https://www.nba.com/stats/
I had to screen scrape some stuff from their website, since some of the endpoints in the python nba_api package are broken now. See the early-nba-trends.ipynb notebook for code.
Nov 05, 2025

Song: Geraldo Pino, "Heavy Heavy Heavy"
Code: https://github.com/csdurfee/scrape_yahoo_odds/. See the push_charts.ipynb notebook.
NBA Push Charts
In the past couple of posts, I've looked at NBA betting data from BetMGM. There are multiple types of bets available on every game. A push chart maps the fair price of a spread bet to the equivalent money line bet. How often does a team that is favored by 3 points win the game outright? It's going to be less often than a team favored by 10 points. The money line should reflect those odds of winning.
You can find a lot of push charts online, but they tend to be based on older NBA data. With more variance due to a lot of 3 point shots, and more posessions per game, I wouldn't expect them to still be accurate.
Push charts are useful for assessing which of two different wagers is the better value. Here's an example of a game where different sportsbooks have different lines for the same game:
Say you want to bet on the Warriors. They have some players out tonight (Nov 5, 2025) so they're the underdogs, but they are also playing the dysfunctional Kangz, so it might be a good value bet. You could take the Warriors at either +3.5 -114, +3 -110, or +2.5 -105. Which bet has the highest expected value? If the Warriors lose by 3, the +3.5 bet would win, but the +3 bet would push (the bet is refunded), and the +2.5 bet would lose. A push chart can give a sense of how valuable the half points from +2.5 to +3, and +3 to +3.5, are. Is the probability of the Warriors losing by exactly 3 -- the value of getting a push -- worth going from -105 to -110?
[edit: the Warriors, without their 3 best players, led for most of the game before eventually losing by 5 after Russell Westbrook had one of his best games in years. So the line was only off by 2 points. The lines are often uncannily close, even when a bunch of weird stuff happens. Sometimes it all kinda cancels out.]
I'm going to do a push chart two different ways, then combine them. For almost every game over the last 4 years, we have the money line and the spread, so we can match them up directly. These will have the vig baked in. And as we saw previously, the money line for favorites has a slightly better expected value than the average bet on the spread. So it's going to end up a little biased.
We can also calculate a push chart without any vig by looking at winning percentage for every spread -- what percent of the time does a +3.5 point underdog actually win the game. It will need some smoothing, since the data will be noisy.
The retail NBA push chart
I matched up the spread and the money line for both the home and the away team on each game, then took the median of those values. Spreads in the range of -0.5 to +0.5 are very rare, as are spreads over -13.5/+13.5, so I've omitted those.
|spread |money line|
|------:|---------:|
| -13.5 | -1000 |
| -12.5 | -750 |
| -11.5 | -650 |
| -10.5 | -550 |
| -9.5 | -450 |
| -8.5 | -375 |
| -7.5 | -300 |
| -6.5 | -250 |
| -5.5 | -225 |
| -4.5 | -190 |
| -3.5 | -160 |
| -2.5 | -140 |
| -1.5 | -120 |
| 1.5 | 100 |
| 2.5 | 115 |
| 3.5 | 135 |
| 4.5 | 155 |
| 5.5 | 180 |
| 6.5 | 200 |
| 7.5 | 240 |
| 8.5 | 290 |
| 9.5 | 340 |
| 10.5 | 400 |
| 11.5 | 475 |
| 12.5 | 525 |
| 13.5 | 625 |
This gives us how BetMGM prices the value of individual points on the spread (with the vig figured in). This is sort of their official price list.
American style odds are symmetrical if there is no vig involved. A -400 bet implies a 4/5 chance of winning, and a +400 bet implies a 1/5 chance of winning. If the -400 bet wins 4/5 of the time and loses 1/5 of the time, the gambler breaks even, and vice versa. So a no-vig money line would be +400/-400.
The odds offered by the sportsbooks are asymmetrical, because they want to make money. We see that +13.5 on the spread maps to a +625 money line, but -13.5 maps to -1000. A +625 bet should win 100/(100+625), or about 14% of the time. A -1000 bet should win 1000/1100, or 91% of the time. Adding those together, we get 91% + 14% = 105%. That extra 5% is called the overround, and is the bookmaker's guaranteed profit, assuming they have equal wagers on both sides.
Here's what that data looks like as a graph, with some smoothing added.
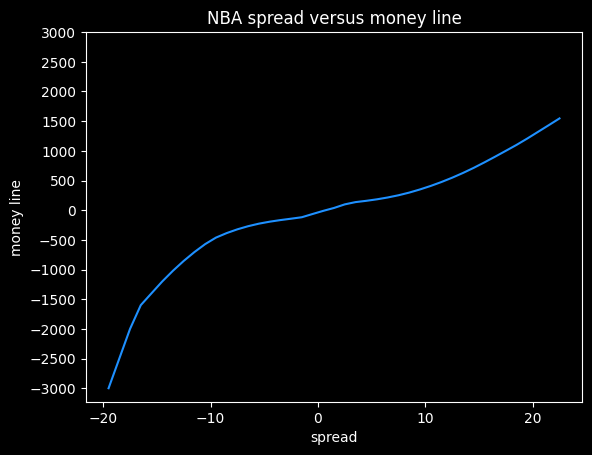
I think this shows the bias against heavy favorites that we saw previously. Note how the line gets much steeper moving from -10 to -20 on the spread, versus moving from +10 to +20.
At -20.5, this graph gives a payout of -5000, but at +20.5, it gives a payout of +1320. The fair payout is somewhere in between those two numbers.
If the fair payout is (-5000/+5000), then the underdog is getting way less of a payout (in essence, paying more in vig) than they should. If the fair payout is closer to (-1360/+1360), then the favorite is paying more in vig than they should. So the asymmetricality gives a clue that sportsbooks aren't splitting the vig down the middle, but it doesn't tell us the fair price.
Push charts based on win frequencies
We can estimate a fair price by going through all the games and see how often a +3.5 underdog wins outright, then convert that percentage to a fair money line. The problem here is that the results will be very noisy. We'd need hundreds or thousands of games at each spread value, and we only have 4,500 or so games overall. So it's gonna be chunky. We'll have to do some smoothing on it, (foreshadowing alert: it will lead to weird results later on)
Here are the win ratios by spread, combining both home and away teams:
| spread| win ratio |
|------:|----------:|
| -13.5 | 0.889764 |
| -12.5 | 0.835616 |
| -11.5 | 0.832487 |
| -10.5 | 0.789474 |
| -9.5 | 0.747212 |
| -8.5 | 0.762763 |
| -7.5 | 0.745763 |
| -6.5 | 0.701299 |
| -5.5 | 0.643892 |
| -4.5 | 0.6 |
| -3.5 | 0.641682 |
| -2.5 | 0.562393 |
| -1.5 | 0.525535 |
| 1.5 | 0.474465 |
| 2.5 | 0.437607 |
| 3.5 | 0.358318 |
| 4.5 | 0.4 |
| 5.5 | 0.356108 |
| 6.5 | 0.298701 |
| 7.5 | 0.254237 |
| 8.5 | 0.237237 |
| 9.5 | 0.252788 |
| 10.5 | 0.210526 |
| 11.5 | 0.167513 |
| 12.5 | 0.164384 |
| 13.5 | 0.110236 |
A team with a -1.5 point spread wins 52.6% of the time, which is very close to the break-even point on standard -110 bets of 52.4%. So a gambler needs to be at least 1.5 points better than Vegas at setting the lines to expect to make money.
These odds have to be symmetrical. If a team favored by -4.5 wins 60% of the time, then a +4.5 point underdog has to win 40% of the time.
Unfortunately, this data is probably too chunky to give good results. -4.5 has a lower win rate than -5.5, which doesn't make any sense. The more negative the spread, the higher the win rate should be. Here's what it looks like with smoothing:
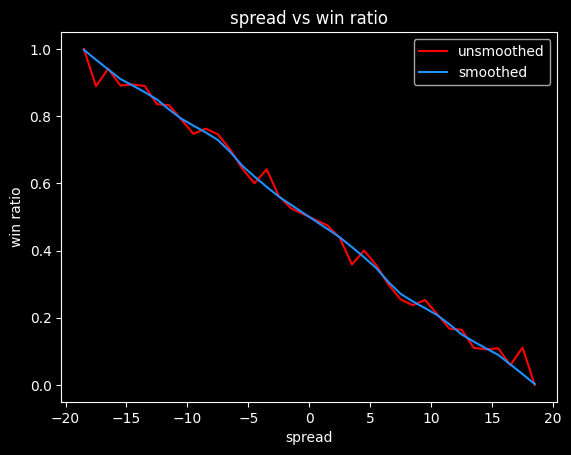
We can convert these winning percentages to fair (no vig) money lines:
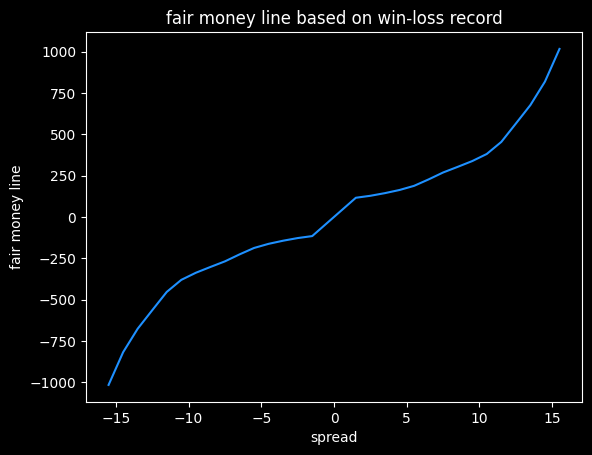
Converting to money lines doesn't break the symmetry. A -4.5 favorite gets a money line of -163, and a 4.5 point underdog gets a money line of +163.
This is just a first attempt. Different ways of smoothing the actual win rates will lead to different results.
|spread |fair ML |
|------:|-------:|
| -13.5 | -677 |
| -12.5 | -565 |
| -11.5 | -454 |
| -10.5 | -381 |
| -9.5 | -338 |
| -8.5 | -303 |
| -7.5 | -269 |
| -6.5 | -227 |
| -5.5 | -188 |
| -4.5 | -163 |
| -3.5 | -144 |
| -2.5 | -128 |
| -1.5 | -116 |
| 1.5 | 116 |
| 2.5 | 128 |
| 3.5 | 144 |
| 4.5 | 163 |
| 5.5 | 188 |
| 6.5 | 227 |
| 7.5 | 269 |
| 8.5 | 303 |
| 9.5 | 338 |
| 10.5 | 381 |
| 11.5 | 454 |
| 12.5 | 565 |
| 13.5 | 677 |
Crossing the streams, and an abrupt ending
What happens if we look at the difference between the no-vig moneylines, and what the sportsbook actually charges? Will it show us the favorite-longshot bias?
It turns out, it doesn't. The win frequency data is too noisy. I spent a lot of time spinning my wheels on it, before realizing I didn't have enough data. I will come back to the subject, though, because failure is more educational than success.
Oct 26, 2025

Song: Pigeonhed, "Glory Bound" (Dave Ruffy Remix)
Code: https://github.com/csdurfee/scrape_yahoo_odds/
A little crowd wisdom
Last week, we saw that for NBA spread bets, the more popular side wins 49.2% of the time. This matches what I've shown before -- the public is generally worse than a coin flip when betting on NBA basketball.
This week, I have some good news. There are some types of bets on the NBA where the public do a little better than expected. Not enough to make money, but better than picking bets by flipping a coin.
Money line bets and rationality
Last time, I looked at money line bets and showed that there is a bias against slight to heavy underdogs, and a possible bias against very heavy favorites. There's a lot I didn't get to, though. What kind of money line bets do the public prefer?
The public takes the home team 63% of the time, which is a little high given the home team wins 55% of games. The public also takes the money line favorite in 96% (4656/4839) of NBA games.
Is that rational or not? We know that favorites are a slightly better deal than underdogs on the money line, so in one sense it is. If someone offered you a free money line bet on the NBA, you should probably pick the favorite. The expected value is less bad than the underdog, so it's a better choice in the long run, and your chances of making some money on the bet are much higher, so it's perhaps a better choice as a single bet as well.
A gambler taking half favorites and half underdogs has a chance at winning 100% of their bets, but someone taking a highly imbalanced number of favorites (or underdogs) will have a whole lot of guaranteed losses. The gambler might correctly pick every single favorite, but close to half of their bets on favorites are still going to be losses.
Getting pigeonholed
Money lines are all at different odds, which complicates things. For this example, let's say the gambler is taking spread bets, with both sides having a roughly equal chance of winning. There are 1230 games in the season, we'll assume the favorite is a slightly better deal, so wins 51% of the time, and the gambler takes the favorite 96% of the time. Over 1230 games, the favorites go 627-603. The gambler takes 1181 favorites and 49 underdogs on the season.
The best they can possibly do on favorites is 627/1181 (53%), assuming they somehow manage to correctly bet on every single favorite that won that season. The gambler captured all of the favorites that won, so the rest of the games left over are underdog winners, meaning they'd go a perfect 49/49 in underdog games. Overall, the best they can do is (627+49)/1230, which is 54.9%. Since the break-even point is 52.4%, most of the profits are coming from the 49 underdog games.
By taking so many favorites, the pigeonhole principle means the gambler has to be perfect just to hit a 54.9% win rate. As I showed in Do you wanna win?, 54.9% is good enough to have a positive expected value on bets, but it's low enough that losing money over 1,230 bets is very possible, even with proper bankroll management. If hitting that number requires you to be perfect, it seems like a bad plan.
Here are the frequencies of odds taken by the public on the money line. There's an awkward gap in the middle. In the American way of writing odds, favorites are always -100 or smaller, and underdogs are always +100 or bigger.
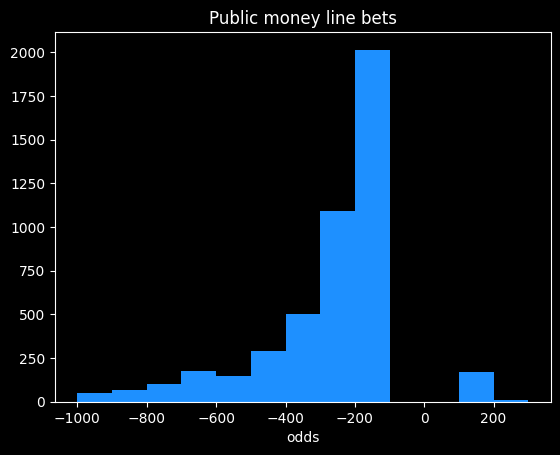
The public mostly takes bets in the -100 to -300 range, which is in the range where money line bets have been a slightly better value than spread bets over the past four seasons, so good for them. The biggest underdog bet the public took in nearly 5,000 bets was at +400 (implying the underdog had a 20% chance of winning.)
The public achieved -2.87% rate of return on money line bets. That's bad compared to the 0% rate of return offered by not betting, but it's better than the -4.5% on spread bets, and way better than the -20% on some types of parlay bets. Someone fading, or taking the opposite bets to the public, would achieve a -6.4% rate of return.
On the rare occasions the public does take the underdog, they make a profit. On those 183 bets, the public notched a +2.43% rate of return. Bets on underdogs will have a high amount of variance, so there could be some luck involved.
Point totals
In addition to who will win the game, gamblers can wager on how many total points will be scored. For instance, if the final score is 120-115, the point total would be 235. If the line was 230, the OVER side would have won, and the UNDER lost.
The point totals are pretty balanced. The over wins 50.6% (2672/5273) of the time. However, the public takes the over 88.3% (4660/4839) of the time.
The public did a little better than a coin flip, winning 51% of over bets, and 54.5% of the 178 under bets.
I was curious whether the percent of bets on one side was correlated with higher winning percentage. If 99% of the public took the over, is that a safer bet than if only 51% of the public took it? I've broken down the public's bets on the over by quartiles:
| start % |
end % |
num games |
win % |
| 50 |
73.9 |
1165 |
50.5% |
| 73.9 |
82.4 |
1164 |
51.4% |
| 82.4 |
88.4 |
1163 |
50.9% |
| 88.4 |
100 |
1168 |
51.5% |
For 1,000 observations, a 95% confidence interval is roughly +/- $\frac{1}{\sqrt{1000}} \approx \frac{1}{\sqrt(33*30)} \approx 3\%$, which is much bigger than the difference between 50.5% and 51.5%. So the difference isn't significant.
Are sportsbooks leaving money on the table?
It's odd to me that the over would win more than 50% of the time when that's the side that usually has the most money on it. That's not a huge imbalance, but the sportsbooks would be making more money if they increased the point totals a bit so the over loses 51% of the time instead.
Gamblers betting on point totals are probably a little more savvy than ones betting the lines. It's kind of an odd thing to bet on. Doesn't matter who won, doesn't matter whether it was a good game or not. All bets are math problems, but point totals are more obviously a math problem than money lines or spreads.
Do point totals tell us anything about the evolution of the NBA?
It's possible sportsbooks haven't kept up with the evolution of the game. NBA point totals have gotten much higher over the past decade due to faster pace, better shooting and more 3 pointers.
Here is a graph of moving averages of the point totals for the past four seasons:
Point totals go down at the end of every year. That's because playoff games tend to be more tightly contested than regular season games. The vertical line is where the playoffs start.
There appears to be an increase in average point totals during the 2021 season, but it's stayed fairly consistent since then, with one notable exception. There's an big dip in point totals during the 2023 season, around game 800. This is almost certainly due to a directive from the NBA telling officials to call fewer fouls. Fans (and presumably gamblers) noticed right away, but the NBA only admitted the change well after the fact. Luckily, nothing has happened since then to further undermine trust in the NBA!